A tale of data migration: moving 195M records from AWS to GCP using Go

When it comes to data migration, a number of different strategies can be adopted. And depending on the limitations faced, well, we have to be creative.
In this article, we’ll explore a real case scenario, presenting a strategy that I’ve successfully implemented.
The problem
Imagine this: you have a REST API, written in Go, running at AWS. There are four tables that, together, have 195 million records. The database is MySQL using InnoDB engine and it’s running at AWS RDS.
This API needs to be migrated to GCP.
Of course, some adaptations on the source code need to be done. Let’s focus on data migration.
Among several possible strategies, I was looking for one that would do the job in the shortest time possible.
One of these options is to use mysqldump. To run it safely on a live database with many active reads and writes, we could do this:
mysqldump -uuser -ppass --single-transaction --routines --triggers --all-databases > backup_db.sql
–single-transaction produces a checkpoint that allows the dump to capture all data prior to the checkpoint while receiving incoming changes. Those incoming changes do not become part of the dump. That ensures the same point-in-time for all tables.
–routines dumps all stored procedures and stored functions.
–triggers dumps all triggers for each table that has them.
The problem is that mysqldump not only takes a long time (thus the database won’t be available during that time), but the SQL dump isn’t immediately compatible with the Google Cloud SQL config available in GCP. Some modifications on the SQL dump are needed make it work.
That said, I would need to take the API offline, do the dump, change the SQL dump file, upload it into a GCP bucket and then import it into Google Cloud SQL.
Time to think about another strategy.
Using Go and CSV files
In a previous article, I’ve demonstrated how to export tables to CSV files using Go. So I gave a try to this approach, and it worked very well.
It’s worth noting that it’s not possible to use LOAD DATA INFILE command with AWS RDS (see https://forums.aws.amazon.com/message.jspa?messageID=162499#162499). Thus I had to read each table sequentially in order to generate the CSV file.
The solution architecture
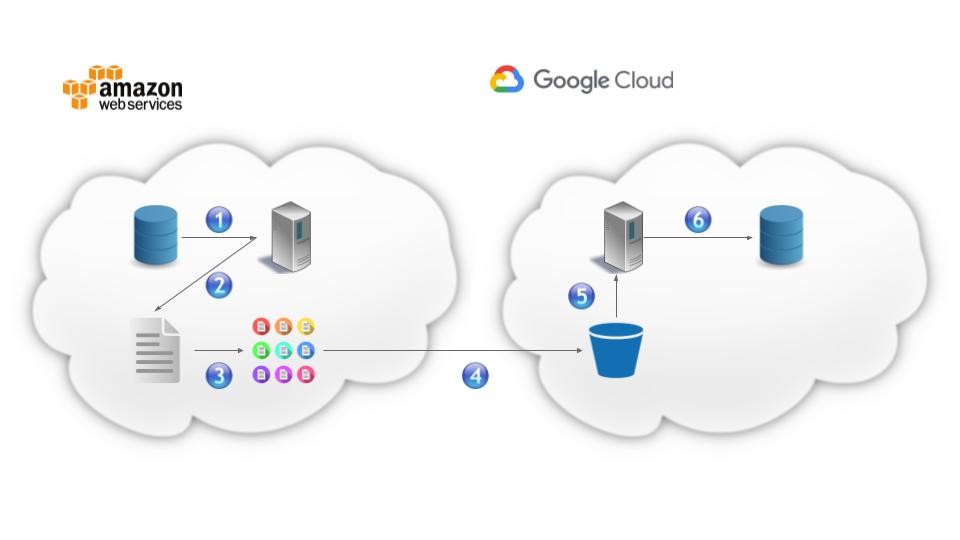
For each of the four tables:
- A Go script running in an EC2 instance connects to a slave database instance and queries the table
- Each returned row is appended to a single CSV file
- The CSV file is split up into smaller CSV files with 1 million lines each
- These smaller CSV files are uploaded to a GCP bucket
- Another Go script running in a Compute Engine instance downloads the CSV files from the GCP bucket
- A worker pool loads each of the CSV files into the Google Cloud SQL instance through a system call to MySQL performing the LOAD DATA INFILE command
Extracting the data
What the script does:
- Reads the configuration file extract.json
- Creates auxiliary directories
- Connects to the database using Go MySQL driver and export each table to its corresponding CSV file
- Makes a system call to Linux’s split command for each CSV file to split them into smaller ones (with 1M lines each); these files are named like this: <table_name>_split_<alphabetic_suffix>. For example, table_1_split_aa, table_1_split_ab and so on.
- Makes a system call to gsutil command-line tool to upload all the CSV files into the GCP bucket
- Deletes the auxiliary directories
This is extract.json:
{
"db": {
"user": "USER",
"pass": "PASS",
"schema": "SCHEMA",
"port": "PORT",
"host": "HOST"
},
"bucket": {
"url": "gs://bucket-name"
},
"queries": {
"table_1": "SELECT field_1, field_2, field_3, field_4, field_5, field_6 FROM table_1",
"table_2": "SELECT field_1, field_2, field_3, field_4, field_5 FROM table_2",
"table_3": "SELECT field_1, field_2 FROM table_3",
"table_4": "SELECT field_1, field_2, field_3 FROM table_4"
},
"misc": {
"linesToSplit": "1000000",
"rawCsvFileDir": "/raw_csv_files",
"splittedCsvFileDir": "/splitted_csv_files"
}
}
And this is extract.go:
/*
This script is responsible for extracting tables to CSV files.
It reads json configuration filed named 'extract.json'.
1 - extract all tables to CSV files;
2 - split each CSV file into smaller ones;
3 - upload them to a bucket at Google Cloud Store.
author: Tiago Melo (tiagoharris@gmail.com)
*/
package main
import (
"database/sql"
"encoding/csv"
"encoding/json"
"fmt"
_ "github.com/go-sql-driver/mysql"
"github.com/stoewer/go-strcase"
"io/ioutil"
"log"
"os"
"os/exec"
"runtime"
"time"
)
type Db struct {
User string `json: "user"`
Pass string `json: "pass"`
Schema string `json: "schema"`
Port string `json: "port"`
Host string `json: "host"`
}
type Bucket struct {
Url string `json: "url"`
}
type Misc struct {
LinesToSplit string `json: "linesToSplit"`
RawCsvFileDir string `json: "rawCsvFileDir"`
SplittedCsvFileDir string `json: "splittedCsvFileDir"`
}
type Config struct {
Db Db `json: "db"`
Bucket Bucket `json: "bucket"`
Queries map[string]string `json: "queries"`
Misc Misc `json: "misc"`
}
var config = Config{}
var configJsonFileName = "extract.json"
type Chronometer struct {
startTime time.Time
}
func (c *Chronometer) Stop() float64 {
endTime := time.Now()
diff := endTime.Sub(c.startTime)
return diff.Seconds()
}
func checkError(message string, err error) {
if err != nil {
log.Fatal(message, err)
}
}
func execCommand(app string, args []string) {
cmd := exec.Command(app, args...)
_, err := cmd.Output()
checkError(fmt.Sprintf("Error executing command %s: ", cmd.Args), err)
}
func extractTableToCsvFile(tableName, query string) int {
rawCsvFileName := fmt.Sprintf("%s/%s.csv", config.Misc.RawCsvFileDir, tableName)
fmt.Printf("Extracting table '%s' into file %s... ", tableName, rawCsvFileName)
c := Chronometer{startTime: time.Now()}
db, err := sql.Open("mysql", fmt.Sprintf("%s:%s@tcp(%s:%s)/%s", config.Db.User, config.Db.Pass, config.Db.Host, config.Db.Port, config.Db.Schema))
defer db.Close()
checkError("Error getting a handle to the database: ", err)
err = db.Ping()
checkError("Error establishing a connection to the database: ", err)
rows, err := db.Query(query)
defer rows.Close()
checkError("Error creating the query", err)
columns, err := rows.Columns()
if err != nil {
checkError("Error getting columns from table: ", err)
}
values := make([]sql.RawBytes, len(columns))
scanArgs := make([]interface{}, len(values))
for i := range values {
scanArgs[i] = &values[i]
}
file, err := os.Create(rawCsvFileName)
defer file.Close()
checkError(fmt.Sprintf("Error creating the file '%s': ", rawCsvFileName), err)
writer := csv.NewWriter(file)
defer writer.Flush()
lines := 0
for rows.Next() {
lines = lines + 1
err = rows.Scan(scanArgs...)
checkError(fmt.Sprintf("Error scanning rows from table '%s': ", tableName), err)
var value string
var line []string
for _, col := range values {
if col == nil || string(col) == "" {
value = "NULL"
} else {
value = string(col)
line = append(line, value)
}
}
err := writer.Write(line)
checkError(fmt.Sprintf("Error writing line to the file '%s': ", rawCsvFileName), err)
}
fmt.Printf("completed in %g seconds. # Lines: %d\n", c.Stop(), lines)
return lines
}
func extractTablesToCsvFiles() {
totalLines := 0
for tableName, query := range config.Queries {
lines := extractTableToCsvFile(tableName, query)
totalLines = totalLines + lines
}
fmt.Printf("\n# Total lines: %d\n\n", totalLines)
}
func createAuxiliaryDirs() {
if _, err := os.Stat(config.Misc.RawCsvFileDir); os.IsNotExist(err) {
os.Mkdir(config.Misc.RawCsvFileDir, os.ModePerm)
}
if _, err := os.Stat(config.Misc.SplittedCsvFileDir); os.IsNotExist(err) {
os.Mkdir(config.Misc.SplittedCsvFileDir, os.ModePerm)
}
}
func splitCsvFileToSmallerFiles(tableName string) {
rawCsvFileName := fmt.Sprintf("%s/%s.csv", config.Misc.RawCsvFileDir, tableName)
splitFileNamePattern := fmt.Sprintf("%s/%s_split_", config.Misc.SplittedCsvFileDir, tableName)
fmt.Printf("Spliting file %s into files with %s lines each... ", rawCsvFileName, config.Misc.LinesToSplit)
c := Chronometer{startTime: time.Now()}
execCommand("/usr/bin/split", []string{"-l", config.Misc.LinesToSplit, rawCsvFileName, splitFileNamePattern})
fmt.Printf("completed in %g seconds.\n", c.Stop())
}
func splitCsvFilesToSmallerFiles() {
for tableName, _ := range config.Queries {
splitCsvFileToSmallerFiles(tableName)
}
}
func cleanUp() {
err := os.RemoveAll(config.Misc.RawCsvFileDir)
checkError(fmt.Sprintf("Error removing directory %s: ", config.Misc.RawCsvFileDir), err)
err = os.RemoveAll(config.Misc.SplittedCsvFileDir)
checkError(fmt.Sprintf("Error removing directory %s: ", config.Misc.SplittedCsvFileDir), err)
}
func uploadCsvFiles() {
fmt.Printf("\nUploading CSV files to '%s'... ", config.Bucket.Url)
c := Chronometer{startTime: time.Now()}
execCommand("/usr/bin/gsutil", []string{"-m", "cp", "-r", fmt.Sprintf("%s/*", config.Misc.SplittedCsvFileDir), config.Bucket.Url})
fmt.Printf("completed in %g seconds.\n", c.Stop())
}
func readConfiguration() {
file, err := ioutil.ReadFile(configJsonFileName)
checkError(fmt.Sprintf("Error reading file %s: ", configJsonFileName), err)
err = json.Unmarshal([]byte(file), &config)
checkError(fmt.Sprintf("File %s is not a valid JSON: ", configJsonFileName), err)
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
c := Chronometer{startTime: time.Now()}
readConfiguration()
createAuxiliaryDirs()
extractTablesToCsvFiles()
splitCsvFilesToSmallerFiles()
uploadCsvFiles()
cleanUp()
fmt.Println("\nEnd. Total time taken:", c.Stop(), "seconds\n")
}
Loading the data
What the script does:
- Reads the configuration file load.json
- Makes a system call to bootstrap the database (if desirable)
- Makes a system call to gsutil command-line tool to download the CSV files from the GCP bucket
- Allocates a worker pool to process the CSV files
- Deletes the CSV files from the file system
Let’s detail a little bit the step #4:
- A worker pool is allocated to process all the CSV files. You can check a very well written tutorial on writing an efficient worker pool in Go here
- A system call to MySQL is made for each CSV file in order to load it using LOAD DATA INFILE command. It’s very important to set SET UNIQUE_CHECKS = 0 and SET FOREIGN_KEY_CHECKS = 0 to improve general performance
This is load.json:
{
"db": {
"user": "USER",
"pass": "PASS",
"schema": "SCHEMA",
"host": "HOST",
"bootstrap": {
"shouldBootstrap": true,
"sqlFile": "schema.sql"
}
},
"bucket": {
"name": "bucket-name",
"url": "gs://bucket-name"
},
"misc": {
"numWorkers": 8
}
}
And this is load.go:
/*
This script is responsible for loading data from CSV files into MySQL tables.
It reads json configuration filed named 'load.json'.
1 - bootstrap the database (optionally);
2 - download the CSV files ftom Google Cloud Store;
3 - load them into MySQL tables.
author: Tiago Melo (tiagoharris@gmail.com)
*/
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"os/exec"
"path/filepath"
"regexp"
"runtime"
"sync"
"time"
)
type Bootstrap struct {
ShouldBootstrap bool `json: "shouldBootstrap"`
SqlFile string `json: "sqlFile"`
}
type Db struct {
User string `json: "user"`
Pass string `json: "pass"`
Schema string `json: "schema"`
Host string `json: "host"`
Bootstrap Bootstrap `json: "bootstrap"`
}
type Bucket struct {
Name string `json: "name"`
Url string `json: "url"`
}
type Misc struct {
NumWorkers int `json: "numWorkers"`
}
type Config struct {
Db Db `json: "db"`
Bucket Bucket `json: "bucket"`
Misc Misc `json: "misc"`
}
var config = Config{}
var jsonFile = "load.json"
var getFilePrefixRegexp = regexp.MustCompile("(\\w+)_split_\\w+")
var jobs = make(chan Job, 10)
var results = make(chan Result, 10)
type Job struct {
id int
fileName string
execTime float64
}
type Result struct {
job Job
}
type Chronometer struct {
startTime time.Time
}
func (c *Chronometer) Stop() float64 {
endTime := time.Now()
diff := endTime.Sub(c.startTime)
return diff.Seconds()
}
func checkError(message string, err error) {
if err != nil {
log.Fatal(message, err)
}
}
func execCommand(app string, args []string) {
cmd := exec.Command(app, args...)
_, err := cmd.Output()
checkError(fmt.Sprintf("Error executing command %s: ", cmd.Args), err)
}
func bootstrapDatabase() {
if config.Db.Bootstrap.ShouldBootstrap {
fmt.Printf("\nBootstrapping database using sql file %s... ", config.Db.Bootstrap.SqlFile)
c := Chronometer{startTime: time.Now()}
execCommand("/usr/bin/mysql", []string{"-u", config.Db.User, fmt.Sprintf("-p%s", config.Db.Pass), "-h", config.Db.Host, "-e", fmt.Sprintf("source %s", config.Db.Bootstrap.SqlFile)})
fmt.Printf("completed in %g seconds.\n", c.Stop())
}
}
func downloadCsvFiles() {
fmt.Printf("\nDownloading CSV files from %s... ", config.Bucket.Url)
c := Chronometer{startTime: time.Now()}
execCommand("/snap/bin/gsutil", []string{"-m", "cp", "-R", config.Bucket.Url, "."})
fmt.Printf("completed in %g seconds.\n", c.Stop())
}
func loadCsvFileIntoTable(fileName string) {
tableName := getFilePrefixRegexp.FindStringSubmatch(fileName)[1]
cmd := "SET UNIQUE_CHECKS = 0; SET FOREIGN_KEY_CHECKS = 0; LOAD DATA LOCAL INFILE '" + fileName + "' INTO TABLE " + tableName + " FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\\n';"
execCommand("/usr/bin/mysql", []string{"-u", config.Db.User, fmt.Sprintf("-p%s", config.Db.Pass), "-D", config.Db.Schema, "-h", config.Db.Host, "--local-infile=TRUE", "--compress=TRUE", "-e", cmd})
err := os.Remove(fileName)
checkError("Error removing file: ", err)
}
func worker(wg *sync.WaitGroup) {
for job := range jobs {
c := Chronometer{startTime: time.Now()}
loadCsvFileIntoTable(job.fileName)
job.execTime = c.Stop()
output := Result{job}
results <- output
}
wg.Done()
}
func createWorkerPool(noOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < noOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate() {
fmt.Print("\nCounting the number of files... ")
files, err := filepath.Glob(fmt.Sprintf("%s/*split*", config.Bucket.Name))
checkError("failed to list files: ", err)
totalFiles := len(files)
fmt.Printf("%d files to be loaded into MySQL.\n", totalFiles)
fmt.Println("\nBegin loading...\n")
for i, f := range files {
job := Job{id: i, fileName: f}
jobs <- job
}
close(jobs)
}
func result(done chan bool) {
for result := range results {
fmt.Printf("JOB id: %d -- completed in %g seconds.\n", result.job.id, result.job.execTime)
}
done <- true
}
func loadCsvFiles() {
go allocate()
done := make(chan bool)
go result(done)
createWorkerPool(config.Misc.NumWorkers)
<-done
}
func cleanUp() {
err := os.RemoveAll(config.Bucket.Name)
checkError("Error removing directory: ", err)
}
func readConfiguration() {
file, err := ioutil.ReadFile(jsonFile)
checkError(fmt.Sprintf("Error reading file %s: ", jsonFile), err)
err = json.Unmarshal([]byte(file), &config)
checkError(fmt.Sprintf("File %s is not a valid JSON: ", jsonFile), err)
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
c := Chronometer{startTime: time.Now()}
readConfiguration()
bootstrapDatabase()
downloadCsvFiles()
loadCsvFiles()
cleanUp()
fmt.Println("\nEnd. Total time taken:", c.Stop(), "seconds\n")
}
Execution times
Let’s check the output from extract.go:
Extracting table 'table_1' into file /raw_csv_files/table_1.csv... completed in 0.020286988 seconds. # Lines: 8
Extracting table 'table_2' into file /raw_csv_files/table_2.csv... completed in 1295.663038824 seconds. # Lines: 185531052
Extracting table 'table_3' into file /raw_csv_files/table_3.csv... completed in 76.077756563 seconds. # Lines: 9608645
Extracting table 'table_4' into file /raw_csv_files/table_4.csv... completed in 0.019862026 seconds. # Lines: 3
# Total lines: 195139708
Spliting file /raw_csv_files/table_1.csv into files with 1000000 lines each... completed in 306.657650259 seconds.
Spliting file /raw_csv_files/table_2.csv into files with 1000000 lines each... completed in 15.757119181 seconds.
Spliting file /raw_csv_files/table_3.csv into files with 1000000 lines each... completed in 0.001309395 seconds.
Spliting file /raw_csv_files/table_4.csv into files with 1000000 lines each... completed in 0.00113417 seconds.
Uploading CSV files to 'gs://bucket-name'... completed in 223.836624095 seconds.
End. Total time taken: 1922.971539241 seconds
real 32m3.453s
user 13m41.323s
sys 5m10.966s
It took only 32 minutes to export 195139708 records to CSV files.
Now let’s check the output from load.go:
Downloading CSV files from gs://bucket-name... completed in 342.608713265 seconds.
Counting the number of files... 197 files to be loaded into MySQL.
Begin loading...
JOB id: 0 -- completed in 118.692096624 seconds.
JOB id: 2 -- completed in 118.693096623 seconds.
JOB id: 5 -- completed in 119.791096625 seconds.
JOB id: 3 -- completed in 117.516796641 seconds.
JOB id: 1 -- completed in 120.892497624 seconds.
JOB id: 7 -- completed in 121.597096025 seconds.
JOB id: 4 -- completed in 121.632696822 seconds.
JOB id: 6 -- completed in 117.890395629 seconds.
JOB id: 8 -- completed in 119.112496627 seconds.
// remaining output omitted for brevity
End. Total time taken: 4204.229570086 seconds.
real 60m10.966s
user 11m5.239s
sys 2m16.476s
JOB id: 10 -- completed in 13.9705277 seconds.
It took only 70 minutes to load 195139708 records into Google Cloud SQL instance.
Conclusion
The whole process of extracting ~ 195M records from AWS RDS and loading into Google Cloud SQ took approximately 1h42m to complete. Very reasonable time!