Building a streaming LLM API in Go with Ollama — and watching it run from a SwiftUI iOS app
In this post, we’ll build a small Go REST API that wraps a local Ollama instance and exposes three endpoints:
GET /api/v1/models— list locally available modelsPOST /api/v1/generate— non-streaming generationPOST /api/v1/generate/stream— token-by-token generation over Server-Sent Events
Then we’ll watch the API in action from a small SwiftUI iOS app.
The full backend code is at https://github.com/tiagomelo/go-llm-api.
Side note: I didn’t start this project from a blank slate. I bootstrapped it from my own open-source Go REST API template,
go-templates/example-rest-api— it already wires up routing, structured logging, middleware, graceful shutdown, Swagger generation, and a sensibleMakefile. That saved me an evening of boilerplate and let me focus on the Ollama-specific bits.
What we’re building
┌────────────────┐ HTTP / SSE ┌──────────────┐ HTTP ┌──────────┐
│ SwiftUI app │ ───────────────────► │ Go API │ ───────────────► │ Ollama │
│ (iOS / iPad) │ ◄─────────────────── │ (this repo) │ ◄─────────────── │ (Docker) │
└────────────────┘ data: {"response":…} └──────────────┘ ndjson chunks └──────────┘
The Go API is the only thing that talks to Ollama. The iOS app talks to the Go API. Streaming flows end-to-end: as Ollama emits each token, the Go server forwards it as an SSE frame, and the iOS app appends it to the screen as it arrives.
Running Ollama
The .env file:
# Ollama Docker Configuration
OLLAMA_CONTAINER_NAME=ollama
OLLAMA_HOST=localhost
OLLAMA_PORT=11434
OLLAMA_MODEL_NAME=llama3.2:1b
DOCKER_NETWORK_NAME=ollama_network
# Ollama HTTP Client Configuration
OLLAMA_HTTP_CLIENT_TIMEOUT_SECONDS=30
OLLAMA_HTTP_CLIENT_KEEP_ALIVE_SECONDS=30
OLLAMA_HTTP_CLIENT_IDLE_CONN_TIMEOUT_SECONDS=90
OLLAMA_HTTP_CLIENT_TLS_HANDSHAKE_TIMEOUT_SECONDS=10
OLLAMA_HTTP_CLIENT_EXPECT_CONTINUE_TIMEOUT_SECONDS=1
# Go LLM API Configuration
GO_LLM_API_PORT=4000
A minimal docker-compose.yml:
services:
ollama:
image: ollama/ollama:latest
container_name: ${OLLAMA_CONTAINER_NAME}
ports:
- "${OLLAMA_PORT}:${OLLAMA_PORT}"
volumes:
- ollama-data:/root/.ollama
networks:
- observability
volumes:
ollama-data:
networks:
observability:
driver: bridge
name: ${DOCKER_NETWORK_NAME}
Pull a small model:
make download-model
This runs ollama pull inside the container and caches the weights in the ollama-data volume.
The Ollama client
A thin wrapper that knows three things — list models, generate, and stream-generate.
The streaming version is the interesting one. It returns two channels: chunks and errors.
type GenerateStreamChunk struct {
Response string `json:"response"`
Done bool `json:"done"`
}
func (c Client) GenerateStream(ctx context.Context, model, prompt string, context ...int) (<-chan GenerateStreamChunk, <-chan error) {
out := make(chan GenerateStreamChunk)
errCh := make(chan error, 1)
go func() {
// Closing both channels on exit lets the consumer's `range` loop
// terminate and signals "no more error coming" on errCh.
defer close(out)
defer close(errCh)
reqBody := GenerateParams{
Model: model,
Prompt: prompt,
Context: context,
Stream: true, // Ollama returns NDJSON, one JSON object per line.
}
// json.Marshal should not fail for this struct; the check exists so
// that if it ever does we surface it instead of silently swallowing.
b, err := json.Marshal(reqBody)
if err != nil {
errCh <- errors.WithMessage(err, "failed to marshal request body")
return
}
// Attaching ctx to the request lets `httpClient.Do` and the body reader
// abort cleanly if the caller cancels — that's what makes Stop work.
req, err := requestBuilderProvider.NewRequestWithContext(
ctx,
http.MethodPost,
c.baseURL+"/generate",
bytes.NewReader(b),
)
if err != nil {
errCh <- errors.WithMessage(err, "failed to create request")
return
}
req.Header.Set("Content-Type", "application/json")
resp, err := c.httpClient.Do(req)
if err != nil {
// On transport error, drain and close any partial body so the
// underlying connection can be returned to the pool instead of
// being orphaned.
if resp != nil && resp.Body != nil {
io.Copy(io.Discard, resp.Body)
resp.Body.Close()
}
errCh <- errors.WithMessage(err, "failed to execute request")
return
}
defer resp.Body.Close()
if isUnsuccessfulStatusCode(resp.StatusCode) {
errCh <- errors.Errorf("unexpected status code: %d", resp.StatusCode)
return
}
// json.Decoder happily reads one JSON object at a time from a stream,
// which matches Ollama's NDJSON output exactly — no manual line
// splitting needed.
decoder := json.NewDecoder(resp.Body)
for {
var chunk GenerateStreamChunk
if err := decoder.Decode(&chunk); err != nil {
// io.EOF is the normal end-of-stream signal; everything else
// is a real decode/transport failure worth reporting.
if err == io.EOF {
return
}
errCh <- errors.WithMessage(err, "failed to decode stream chunk")
return
}
// Send the chunk, but stay cancellable: if the consumer is gone
// or the caller cancelled ctx, exit promptly instead of blocking
// forever on `out <- chunk`.
select {
case out <- chunk:
case <-ctx.Done():
errCh <- ctx.Err()
return
}
// Ollama marks the last chunk with done=true. Returning here
// closes `out` via the deferred close and ends the consumer's
// range loop cleanly.
if chunk.Done {
return
}
}
}()
return out, errCh
}
Two things to notice:
- We use
json.Decoder.Decodein a loop — Ollama emits NDJSON withstream: true, one JSON object per line, and the decoder happily reads them one at a time. - The
selectlets the consumer cancel mid-stream. Pass a cancellable context, cancel it, and the goroutine exits cleanly without leaking the connection.
The HTTP handler
The handler converts those Go channels into an SSE stream the browser/app can consume:
w.Header().Set("Content-Type", "text/event-stream")
w.Header().Set("Cache-Control", "no-cache")
w.Header().Set("Connection", "keep-alive")
w.Header().Set("X-Accel-Buffering", "no")
flusher, ok := w.(http.Flusher)
if !ok {
web.RespondWithError(w, http.StatusInternalServerError, "streaming not supported")
return
}
w.WriteHeader(http.StatusOK)
flusher.Flush()
chunks, errs := h.client.GenerateStream(
r.Context(),
generateReq.Model,
generateReq.Prompt,
generateReq.Context...,
)
for {
select {
case chunk, ok := <-chunks:
if !ok {
return
}
if chunk.Done {
fmt.Fprintf(w, "event: done\ndata: {\"done\":true}\n\n")
flusher.Flush()
return
}
// json.Marshal should not fail for this struct (only string/bool fields).
// This is a defensive check to avoid breaking the SSE stream on unexpected changes.
b, err := json.Marshal(chunk)
if err != nil {
fmt.Fprintf(w, "event: error\ndata: {\"error\":\"failed to marshal stream chunk\"}\n\n")
flusher.Flush()
return
}
fmt.Fprintf(w, "data: %s\n\n", b)
flusher.Flush()
case err, ok := <-errs:
if ok && err != nil {
b, _ := json.Marshal(map[string]string{
"error": err.Error(),
})
fmt.Fprintf(w, "event: error\ndata: %s\n\n", b)
flusher.Flush()
return
}
case <-r.Context().Done():
return
}
}
The wire format ends up being:
data: {"response":"Hello","done":false}
data: {"response":", ","done":false}
data: {"response":"world!","done":false}
event: done
data: {"done":true}
Each data: frame is one token. The terminating event: done tells the client to stop.
A subtle gotcha: gzip vs SSE
The first time I tested this end-to-end, the iOS app showed nothing. The Ollama logs showed a successful 12-second generation, but no tokens appeared on the device — and then the entire response appeared at the very end.
The cause? A piece of middleware applied globally:
router.Use(
middleware.Logger(c.Log),
middleware.Compress, // this one
middleware.PanicRecovery,
)
middleware.Compress is a thin wrapper around gorilla/handlers.CompressHandler. It gzip-compresses every response. Combined with SSE, that means:
- Each
flusher.Flush()call flushes into the gzip writer, not the network socket. - The gzip writer waits for enough data to compress before flushing to the socket.
- The client receives nothing until the server closes the stream.
Compression and streaming are mutually exclusive. Pick one per response.
The fix is to skip compression for SSE clients:
func Compress(next http.Handler) http.Handler {
compressed := handlers.CompressHandler(next)
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if strings.Contains(r.Header.Get("Accept"), "text/event-stream") {
next.ServeHTTP(w, r)
return
}
compressed.ServeHTTP(w, r)
})
}
Clients that ask for text/event-stream go straight through; everyone else still gets gzip.
Another subtle gotcha: http.Client.Timeout vs streaming
The next surprise came once the iOS app worked for short answers. Anything longer than ~30 seconds got cut off mid-stream with this error bubbling up from the SSE error frame:
Stream error: failed to decode stream chunk: context deadline exceeded (Client.Timeout or context cancellation while reading body)

The culprit was the innocent-looking constructor I had for the Ollama HTTP client:
var newHTTPClient httpClientFactory = func(timeout time.Duration) httpClient {
return &http.Client{Timeout: timeout}
}
The Timeout field looks like it would only bound “how long do I wait for the server to respond” — but it actually covers the entire request lifetime: connection setup, TLS, headers, and body. So as soon as a streaming body ran past 30s, the client tore the connection down, exactly the same way it would for an unresponsive server.
http.Client.Timeoutis a wall-clock cap on the whole request, body reads included. It’s the wrong knob for streaming.
The fix is to push the timeout down to the Transport, where it can apply only to phases that should be bounded — dialing and reading response headers — and leave the body untouched:
var newHTTPClient httpClientFactory = func(params HTTPClientParams) httpClient {
return &http.Client{
Transport: &http.Transport{
Proxy: http.ProxyFromEnvironment,
DialContext: (&net.Dialer{
Timeout: params.Timeout,
KeepAlive: params.KeepAlive,
}).DialContext,
ResponseHeaderTimeout: params.Timeout,
IdleConnTimeout: params.IdleConnTimeout,
TLSHandshakeTimeout: params.TLSHandshakeTimeout,
ExpectContinueTimeout: params.ExpectContinueTimeout,
},
}
}
Now OLLAMA_HTTP_CLIENT_TIMEOUT_SECONDS=30 means “give up if Ollama doesn’t even start answering within 30s”, not “give up after 30s of streaming.” The body can take as long as the model takes; the per-request context.Context is what actually bounds it. That’s also what keeps the iOS Stop button working — cancel the ctx, the read aborts, the goroutine exits cleanly.
Verifying with curl
Before bringing in any client, make sure the server actually streams:
curl -N -s \
-H "Accept: text/event-stream" \
-H "Content-Type: application/json" \
-X POST http://localhost:4000/api/v1/generate/stream \
-d '{"model":"llama3.2:1b","prompt":"say hello"}'
The -N flag is essential — without it, curl buffers the response and you’ll see the same one-shot behavior the broken middleware gave us. You should see frames trickle in:
data: {"response":"Hello","done":false}
data: {"response":".","done":false}
event: done
data: {"done":true}
If that works, the problem from there on is on the client side.
Swagger documentation
Because the project is built on top of go-templates/example-rest-api, Swagger generation is already wired up — I just had to annotate the new Ollama handlers. Two make targets do everything:
make swagger # regenerate doc/swagger.json from code annotations
make swagger-ui # launch Swagger UI in Docker on port 80
Once it’s up, http://localhost becomes an interactive playground for all three endpoints, including the streaming one — you can hit Try it out and watch the SSE frames come back live:
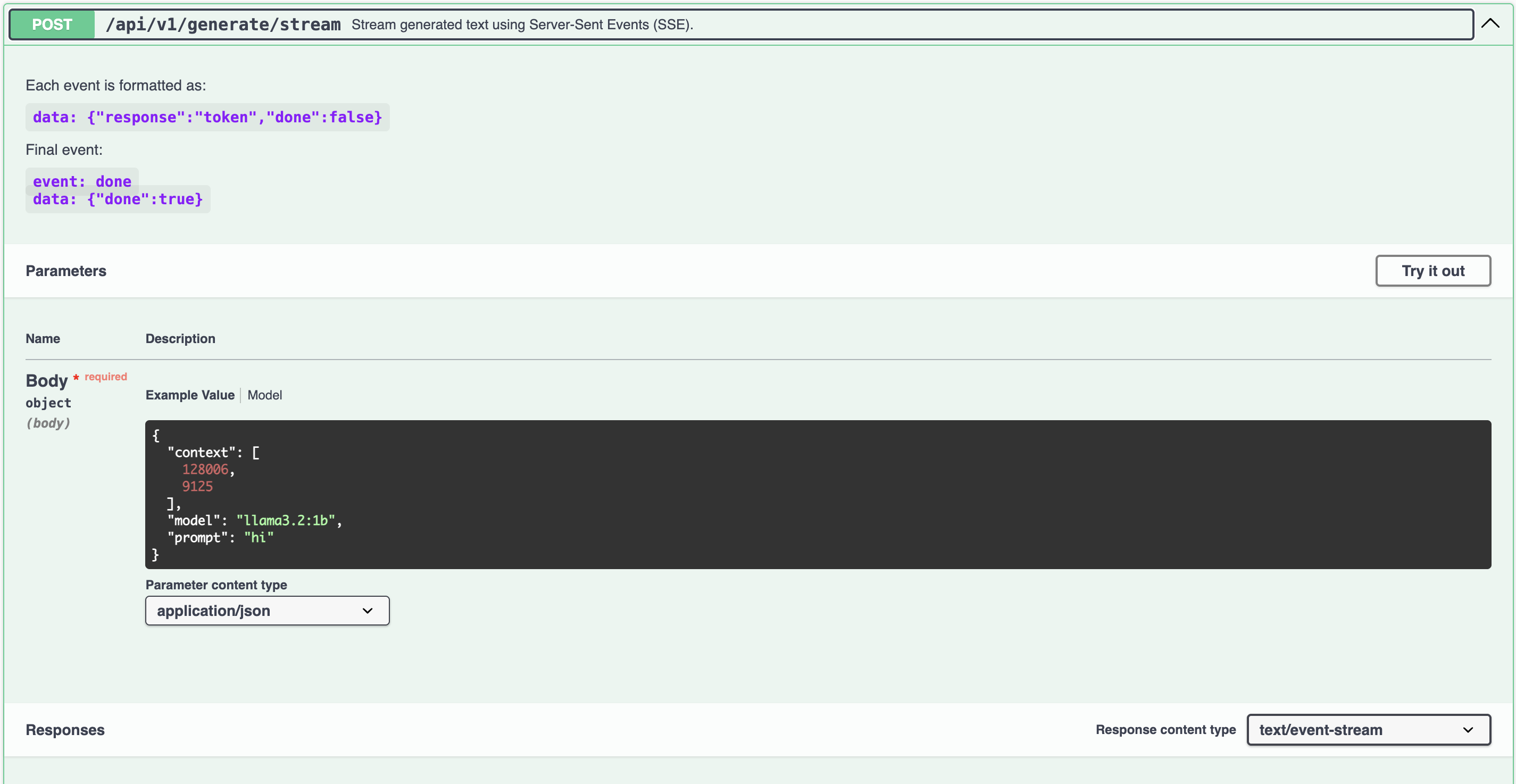
Having Swagger essentially for free was the main reason I started from the template instead of from scratch.
Tests
Both the Ollama client and the HTTP handler have full unit-test coverage. The streaming tests in particular are worth a look because they exercise an AsyncThrowingStream-like Go pattern: drain the chunks channel via for chunk := range out, then read the error channel afterwards.
out, errCh := client.GenerateStream(ctx, "llama3.2:1b", "Hello")
for chunk := range out {
chunks = append(chunks, chunk)
}
require.NoError(t, <-errCh)
There’s also a context-cancellation test that verifies the goroutine cleanly returns ctx.Err() mid-stream — important because a hung stream goroutine is a slow leak.
ctx, cancel := context.WithCancel(context.Background())
out, errCh := client.GenerateStream(ctx, "llama3.2:1b", "Hello")
first, _ := <-out
cancel()
for range out {}
err := <-errCh
require.ErrorIs(t, err, context.Canceled)
A note on coverage
The first time I checked the HTML coverage report for these tests, half the covered branches showed up in grey — easy to mistake for uncovered code. Turns out:
go test -raceforces-covermode=atomic, even if you set-covermode=setexplicitly. Atomic mode produces frequency-tinted output: grey is “covered once.”
The fix is to split the make targets — test runs the race detector, coverage runs without it:
test:
@ go test -v -race ./... -count=1
coverage:
@ go test -covermode=set -count=1 \
-coverpkg=$$(go list ./... | tr '\n' ',') \
-coverprofile=coverage.out ./...
@ go tool cover -html=coverage.out -o coverage.html
Now the report is binary: red for uncovered, green for covered.
Seeing it in action
Time for the fun part. The iOS app is a small SwiftUI chat client:
- a Model picker at the top, populated from
/api/v1/models, - a scrollable chat history with user and assistant bubbles,
- a message input with a combined Send / Stop button,
- a Stream response toggle that decides which endpoint to call:
- on →
/api/v1/generate/stream(SSE, token-by-token), - off →
/api/v1/generate(single JSON response).
- on →
- a trash icon in the nav bar to wipe the chat.
I started the backend, tailed its logs, and drove the app from the simulator. Each interaction below is paired with the matching server-side entries.
Booting the API
$ make run-api
[+] Running 1/0
✔ Container ollama Running 0.0s
{"time":"2026-05-12T09:24:24.145201-03:00","level":"INFO","msg":"Config read successfully: &{ollama localhost 11434 30 ollama_network}"}
{"time":"2026-05-12T09:24:24.145366-03:00","level":"INFO","msg":"API listening on :4000"}
make run-api makes sure the Ollama container is up, then starts the Go server. Within seconds the iOS app opens and pulls the model list to populate the Model picker:
{"time":"2026-05-12T09:24:42.97345-03:00","level":"INFO","msg":"request started","method":"GET","path":"/api/v1/models","remoteaddr":"[::1]:62071"}
{"time":"2026-05-12T09:24:43.00456-03:00","level":"INFO","msg":"request completed","method":"GET","path":"/api/v1/models","remoteaddr":"[::1]:62071","since":33329000}
(since is in nanoseconds — that’s ~33 ms.)
Streaming on — tokens arrive live
With Stream response enabled, hitting Send opens an SSE connection to /api/v1/generate/stream. Tokens land in the chat bubble as Ollama emits them:

{"time":"2026-05-12T09:25:04.660262-03:00","level":"INFO","msg":"request started","method":"POST","path":"/api/v1/generate/stream","remoteaddr":"[::1]:62118"}
{"time":"2026-05-12T09:25:24.160918-03:00","level":"INFO","msg":"request completed","method":"POST","path":"/api/v1/generate/stream","remoteaddr":"[::1]:62118","since":19500641000}
The full generation took about 19.5 seconds end-to-end, but the user-perceived latency is essentially the time to the first token — the rest arrived progressively while the response was already on screen.
Streaming off — wait for the full response
Flipping the toggle off routes the same kind of prompt through /api/v1/generate instead. Same model, same backend, very different experience:

{"time":"2026-05-12T09:26:59.06684-03:00","level":"INFO","msg":"request started","method":"POST","path":"/api/v1/generate","remoteaddr":"[::1]:62410"}
{"time":"2026-05-12T09:27:11.158067-03:00","level":"INFO","msg":"request completed","method":"POST","path":"/api/v1/generate","remoteaddr":"[::1]:62410","since":12091226000}
About 12 seconds of empty screen, then the full answer lands in one piece. Same code path on the iOS side except for the URL and the decoder; from the server you don’t see any per-token activity either, because we’re just proxying a single JSON body.
This side-by-side is the most useful demo of the two: same Go API, two endpoints, two very different user-perceived latencies.
Stopping mid-stream
The Stop button cancels the iOS task, which cancels the URLSession, which closes the SSE connection — and the Go handler exits via r.Context().Done():

Final thoughts
What we end up with:
- A Go REST API that wraps Ollama with a clean, testable client.
- A real SSE endpoint with proper context cancellation and a working backpressure model via channels.
- A middleware chain that knows when to not compress.
- A test suite that exercises the streaming and cancellation paths the same way a real client would.
- A SwiftUI chat app that consumes either the streaming or the non-streaming endpoint with a single toggle (more on the iOS side in a future post).
Closing insight
Streaming is mostly about not doing things: not buffering, not compressing, not waiting. The hard part is finding which layer is doing the buffering for you, and turning it off.