Spring Boot Batch: exporting millions of records from a MySQL table to a CSV file without eating all your memory
As stated in my previous posts ( here and here), Spring Boot came to ease the development of different kinds of applications. This time we’ll write a standalone application integrating Spring Batch that exports data from a MySQL table to a CSV file.
Introduction
My first experience with Spring Batch was back in 2012. At that time, configuration was primarily declarative and verbose, having to write lengthy XML files.
As my experience with Spring Boot grows, I decided to see how I could integrate Spring Batch with it in order to get it up and running with clear and minimal configuration.
The project
I’ve wrote a small Spring Boot project that uses Spring Batch to export all data from a MySQL table to a CSV file.
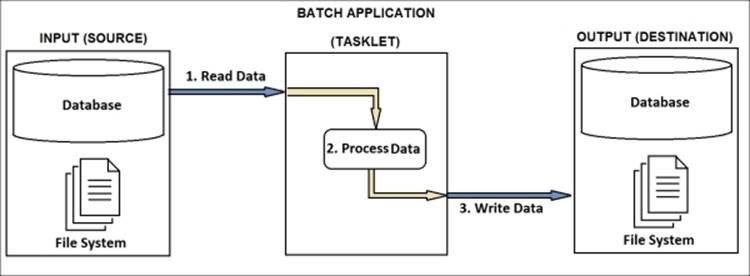
The logical steps are:
- read all data from the table;
- process the data, applying some transformation on it;
- write the transformed data to a CSV file.
So, suppose that we have a ‘user’ table. A ‘user’ has name, email, phone number and birth date. In this example, we will read all users, change their name and email to upper case and then write them in a CSV file.
Creating the project
Spring Initializr is our start point:
We’ve choose the following dependencies:
- MySQL: to add ‘mysql-connector-java’ jar to our project;
- Batch: Starter for using Spring Batch.
Setting up the database
This is our ‘user’ table:
CREATE TABLE `user` (
`id` int(11) NOT NULL auto_increment,
`name` varchar(50) NOT NULL,
`email` varchar(50) NOT NULL,
`phone_number` varchar(20) NOT NULL,
`birth_date` date,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
And this is our ‘src/main/resources/application.yml’ file:
spring:
datasource:
url: jdbc:mysql://localhost:3306/spring_batch_example?useSSL=false
username: root
password:
batch:
initialize-schema: ALWAYS
By setting ‘spring.batch.initialize-schema’ as ‘ALWAYS, all tables that Spring Batch uses to manage jobs executions will be created automatically at startup.
As the article’s title says, our table will contain 10 million records. But how can we initialize it in a fast and reliable way?
MySQL has a command called LOAD DATA INFILE that reads rows from a text file into a table at a very high speed. If we have a CSV file, we can read it this way:
mysql> LOAD DATA LOCAL INFILE 'inserts.csv' INTO TABLE user FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
And this is the result: about one minute to insert 10 million records. Not bad, right?
mysql> LOAD DATA LOCAL INFILE 'inserts.csv' INTO TABLE user FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
Query OK, 10000000 rows affected (1 min 5.62 sec)
Records: 10000000 Deleted: 0 Skipped: 0 Warnings: 0
This a utility class to generate the mentioned CSV file:
package com.tiago.util;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Utility class to generate a CSV file used to initialize a table.
*
* @author Tiago Melo (tiagoharris@gmail.com)
*
*/
public class DBPopulator {
private static int MAX_WORKERS = 8;
private static AtomicInteger COUNT = new AtomicInteger(0);
private static final int AMOUNT = 10_000_000;
private static final String CSV_LINE = "%1$s,\"name %1$s\",\"email@email.com\",\"99999999\",\"1984-01-01\"\n";
private static final String FILE_NAME = "inserts.csv";
public static void main(String[] args) throws IOException {
System.out.println("Writing file " + FILE_NAME);
BufferedWriter writer = new BufferedWriter(new FileWriter(FILE_NAME));
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(MAX_WORKERS);
for (int i = 0; i < AMOUNT; i++) {
executor.submit(() -> {
writer.write(String.format(CSV_LINE, COUNT.incrementAndGet()));
return null;
});
}
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
System.err.println("Pool did not terminate");
}
}
} catch (InterruptedException e) {
executor.shutdownNow();
} finally {
writer.close();
System.out.println("Finished. " + COUNT.get() + " insert statements were generated.");
}
}
}
The classes
Model
package com.tiago.model;
import java.time.LocalDate;
/**
* Model class for table "User"
*
* @author Tiago Melo (tiagoharris@gmail.com)
*
*/
public class User {
private Integer id;
private String name;
private String email;
private String phoneNumber;
private LocalDate birthDate;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
public LocalDate getBirthDate() {
return birthDate;
}
public void setBirthDate(LocalDate birthDate) {
this.birthDate = birthDate;
}
}
Configuration
This is all that we need in order to setup Spring Batch. Very clean and neat, as opposed to prior XML configurations:
package com.tiago.configuration;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.JdbcCursorItemReader;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor;
import org.springframework.batch.item.file.transform.DelimitedLineAggregator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import com.tiago.batch.processor.UserItemProcessor;
import com.tiago.batch.rowmapper.UserRowMapper;
import com.tiago.model.User;
/**
* Configuration class for batch processing.
*
* @author Tiago Melo (tiagoharris@gmail.com)
*
*/
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
public DataSource dataSource;
private static final int CHUNK_SIZE = 10_000;
@Bean
public JdbcCursorItemReader<User> reader() {
JdbcCursorItemReader<User> reader = new JdbcCursorItemReader<User>();
reader.setDataSource(dataSource);
reader.setSql("SELECT id,name,email,phone_number,birth_date FROM user");
reader.setRowMapper(new UserRowMapper());
return reader;
}
@Bean
public FlatFileItemWriter<User> writer() {
FlatFileItemWriter<User> writer = new FlatFileItemWriter<User>();
writer.setResource(new FileSystemResource("users.csv"));
writer.setLineAggregator(new DelimitedLineAggregator<User>() {
{
setDelimiter(",");
setFieldExtractor(new BeanWrapperFieldExtractor<User>() {
{
setNames(new String[] { "id", "name", "email", "phoneNumber", "birthDate" });
}
});
}
});
return writer;
}
@Bean
public UserItemProcessor processor() {
return new UserItemProcessor();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1").<User, User>chunk(CHUNK_SIZE)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
@Bean
public Job exportUserJob() {
return jobBuilderFactory.get("exportUserJob")
.incrementer(new RunIdIncrementer())
.flow(step1())
.end()
.build();
}
}
Let’s dig in:
@Bean
public JdbcCursorItemReader<User> reader() {
JdbcCursorItemReader<User> reader = new JdbcCursorItemReader<User>();
reader.setDataSource(dataSource);
reader.setSql("SELECT id,name,email,phone_number,birth_date FROM user");
reader.setRowMapper(new UserRowMapper());
return reader;
}
Here we set up JdbcCursorItemReader, a simple item reader implementation that opens a JDBC cursor and continually retrieves the next row in the ResultSet.
This is ‘UserRowMapper’ class, used to map a row in the ResultSet to a User object:
package com.tiago.batch.rowmapper;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
import com.tiago.model.User;
/**
* Maps a row into a {@link User} object.
*
* @author Tiago Melo (tiagoharris@gmail.com)
*
*/
public class UserRowMapper implements RowMapper<User> {
/* (non-Javadoc)
* @see org.springframework.jdbc.core.RowMapper#mapRow(java.sql.ResultSet, int)
*/
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setName(rs.getString("name"));
user.setEmail(rs.getString("email"));
user.setPhoneNumber(rs.getString("phone_number"));
user.setBirthDate(rs.getDate("birth_date").toLocalDate());
return user;
}
}
Now let’s take a look at how we set up the writer:
@Bean
public FlatFileItemWriter<User> writer() {
FlatFileItemWriter<User> writer = new FlatFileItemWriter<User>();
writer.setResource(new FileSystemResource("users.csv"));
writer.setLineAggregator(new DelimitedLineAggregator<User>() {
{
setDelimiter(",");
setFieldExtractor(new BeanWrapperFieldExtractor<User>() {
{
setNames(new String[] { "id", "name", "email", "phoneNumber", "birthDate" });
}
});
}
});
return writer;
}
So after execution a file called ‘user.csv’ will be generated, containing all data from ‘user’ table.
Now we set up the processor:
@Bean
public UserItemProcessor processor() {
return new UserItemProcessor();
}
And this is the processor. We’ll change the name and email of every user to upper case:
package com.tiago.batch.processor;
import org.springframework.batch.item.ItemProcessor;
import com.tiago.model.User;
/**
* Process the {@link User} object, applying some transformation.
*
* @author Tiago Melo (tiagoharris@gmail.com)
*
*/
public class UserItemProcessor implements ItemProcessor<User, User> {
/* (non-Javadoc)
* @see org.springframework.batch.item.ItemProcessor#process(java.lang.Object)
*/
@Override
public User process(User user) throws Exception {
user.setName(user.getName().toUpperCase());
user.setEmail(user.getEmail().toUpperCase());
return user;
}
}
Next, we define the step that reads, transforms and writes the data. For 10 million records, we define ‘CHUNK_SIZE’ as 10 thousand:
@Bean
public Step step1() {
return stepBuilderFactory.get("step1").<User, User>chunk(CHUNK_SIZE)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
Finally, we configure a job what will run the step defined above:
@Bean
public Job exportUserJob() {
return jobBuilderFactory.get("exportUserJob")
.incrementer(new RunIdIncrementer())
.flow(step1())
.end()
.build();
}
It’s show time!
As I’ve mentioned in the beginning, our main goal is to export millions of records without eating up all the memory.
We’ll see two approaches and measure memory consumption using JProfiler to compare the difference between then.
I’m running it on a laptop with 15GB of RAM.
First (and naive) approach
As we saw earlier, we set up our reader selecting all records from ‘user’ table without any extra configuration. Let’s see what happens.
Let’s fire up the application:
$ mvn spring-boot:run
Looking at the console, it took almost sevent minutes to complete:
2019-02-24 20:18:29.991 INFO 22291 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [step1]
2019-02-24 20:25:08.575 INFO 22291 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=exportUserJob]] completed with the following parameters: [{run.id=40}] and the following status: [COMPLETED]
Let’s check an excerpt of memory consumption:
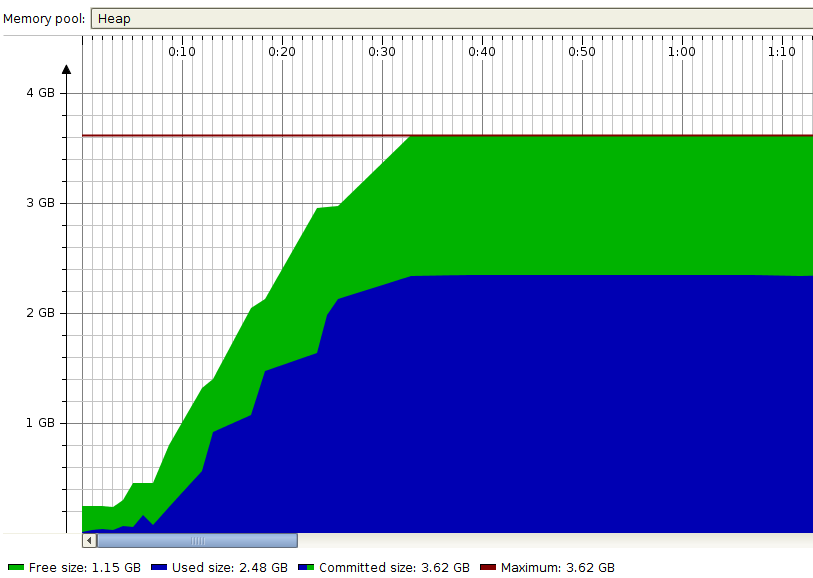
Wow. Almost 2.5GB of consumed memory.
Well… why such poor performance?
Naive approaches to fetching and processing a larger amount of data (by larger, I mean datasets that do not fit into the memory of the running application) from the database will often result with running out of memory. This is especially true when using ORMs / abstraction layers such as JPA where you don’t have access to lower level facilities that would allow you to manually manage how data is fetched from the database. Typically, at least with the stack that I’m usually using - MySQL, Hibernate/JPA and Spring Data - the whole ResultSet of a large query will be fetched entirely either by MySQL’s JDBC driver or one of the aforementioned frameworks that come after it. This will lead to OutOfMemory exceptions if the ResultSet is sufficiently large.
Second (and more efficient) approach
According to MySQL’s JDBC driver’s documentation:
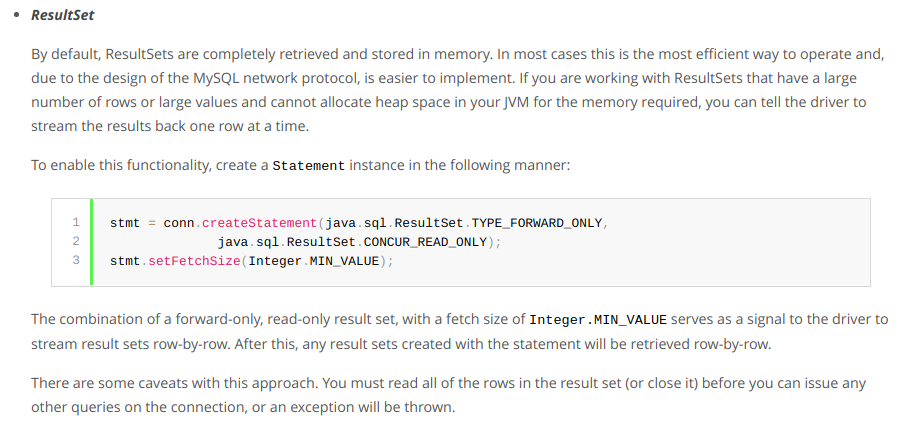
Seems that when using MySQL in order to avoid a large resultset in the memory we need to satisfy three conditions:
- Forward-only resultset
- Read-only statement
- Fetch-size set to Integer.MIN_VALUE
Since we’re using JdbcCursorItemReader, as we can see in its source code, ‘ResultSet.TYPE_FORWARD_ONLY’ and ‘ResultSet.CONCUR_READ_ONLY’ are set in the statement.
Now let’s do a small change on our reader setup:
@Bean
public JdbcCursorItemReader<User> reader() {
JdbcCursorItemReader<User> reader = new JdbcCursorItemReader<User>();
reader.setDataSource(dataSource);
reader.setFetchSize(Integer.MIN_VALUE);
reader.setVerifyCursorPosition(false);
reader.setSql("SELECT id,name,email,phone_number,birth_date FROM user");
reader.setRowMapper(new UserRowMapper());
return reader;
}
By setting fetch size to ‘Integer.MIN_VALUE’ we satisfy the three conditions mentioned above. And calling ‘reader.setVerifyCursorPosition(false)’ will avoid ‘com.mysql.jdbc.RowDataDynamic$OperationNotSupportedException: Operation not supported for streaming result sets’ exception.
Let’s fire up the application again:
$ mvn spring-boot:run
Looking at the console, it took only 54 seconds to export 10 million records:
2019-02-24 21:27:44.069 INFO 30747 --- [ restartedMain] o.s.batch.core.job.SimpleStepHandler : Executing step: [step1]
2019-02-24 21:28:38.144 INFO 30747 --- [ restartedMain] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=exportUserJob]] completed with the following parameters: [{run.id=41}] and the following status: [COMPLETED]
Let’s check memory consumption:
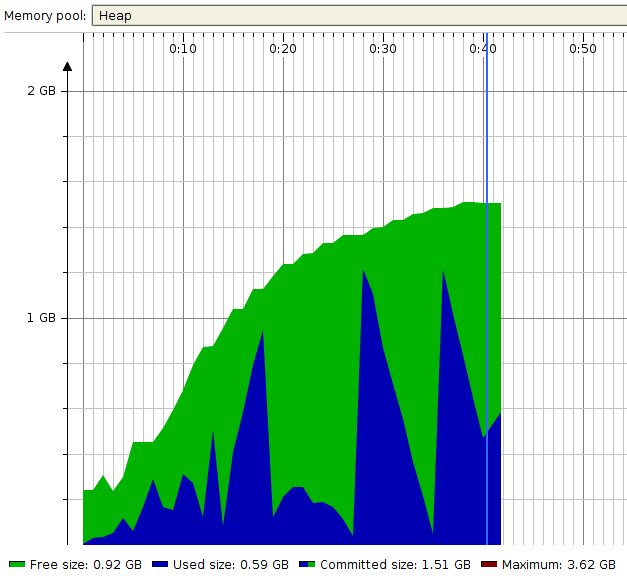
Great! It consumed much less memory and performed very well.
This is an excerpt of the generated CSV file:
1,NAME 1,EMAIL@EMAIL.COM,99999999,1984-01-01
2,NAME 2,EMAIL@EMAIL.COM,99999999,1984-01-01
3,NAME 3,EMAIL@EMAIL.COM,99999999,1984-01-01
...
Conclusion
Through this simple example we learnt how to integrate Spring Batch with Spring Boot to build a fast as robust solution to export data from a table to a file. We also saw important configuration details of MySQL’s JDBC driver to avoid high memory consumption.
Download the source code
Here: https://bitbucket.org/tiagoharris/spring-batch-example/src/master/